DATABASE
Introduction :
TonguExpert aims to provide an integrate resource platform to archive tongue images and extract tongue phenotypes. Here, we release a database (DOWNLOAD HERE (~302M)) currently contains de-identified tongue images and tongue phenotypes from a cohort of 5,992 Chinese individuals, with a male to female ratio of 1: 1.26, with an average age of 46.55±13.21. A model integrated with multiple deep learning algorithms extracts phenotypes from raw images following the workflow below. Details of the model parameters can be found in our manuscript.
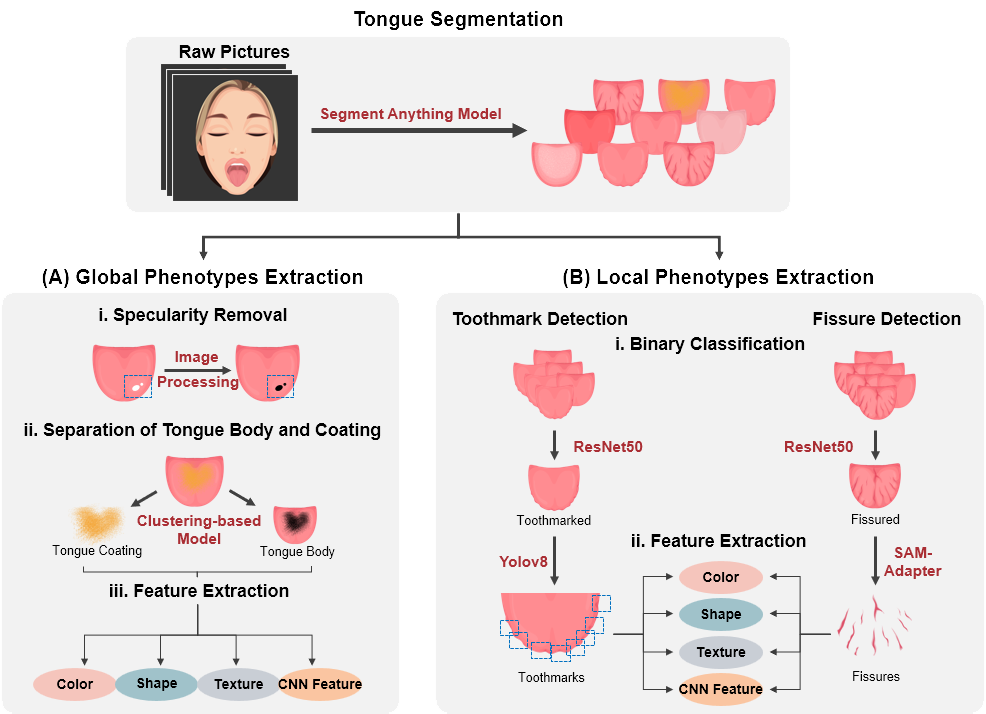
Tongue Phenotypes:
The database includes the following 697 phenotypes:
- 9 Categorical phenotypes:
- 1) Manual label of color of tongue coating, tongue body, tongue fissures and tooth marks. The labels have been meticulously labelled and confirmed by two professional experts.
- 2) Predicted label of color of tongue coat, tongue body, tongue fissures, tooth marks, and greasy coating.
- 688 Continuous phenotypes:
- Color phenotypes and morphological phenotypes including texture, shape, and CNN network features of:
- 1) tongue coat, tongue body, and entire tongue
- 2) fissure(if available)
- 3) tooth marks (if available)
DOWNLOAD:

ANALYSIS
TonguExpert provides an integrated online platform based on multiple deep learning algorithms, designed to assist users in extracting fine-grained tongue phenotypic features and conducting classification from images containing human tongue features. Leveraging the effectiveness of multi-platform collaboration in precise graphic processing, we employ a series of deep learning algorithms for tongue segmentation, specularity removal, tongue coat and tongue body segmentation, color phenotype extraction, and morphological feature extraction (including tooth marks and tongue fissures) from raw images. Algorithms used by the workflow include SAM, ResNet50, YoloV8, SAM-adaptor, and VGG network are integrated with our scripts. The workflow have been described in DATABASE. See HEADER file for the output file format.
Please upload tongue image to extract phenotypes
Example: example.jpg Analysis Result: https://www.biosino.org/TonguExpert/analysis/detail/example
Related Algorithms:
- Segment anything model (SAM): Kirillov, A. et al. Segment Anything. 2023 IEEE/CVF International Conference on Computer Vision (ICCV) (2023) doi:10.1109/iccv51070.2023.00371.
- ResNet50: He, K., Zhang, X., Ren, S. & Sun, J. Deep Residual Learning for Image Recognition. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016) doi:10.1109/cvpr.2016.90.
- SAM-Adapter: Chen, T. et al. SAM-Adapter: Adapting Segment Anything in Underperformed Scenes. 2023 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW) (2023) doi:10.1109/iccvw60793.2023.00361.
- Yolo v8: https://github.com/ultralytics/ultralytics
- VGG: Simonyan, K. & Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arxiv:1409.1556[cs.CV] (2014).

CONTACT US
All comments and suggestions are welcome, if you find any error in data or bug in web service, please kindly report it to us.
Contact Information:
- Lab Homepage: https://www.biosino.org/humanphenomics/
- Institution: CAS Key Laboratory of Computational Biology, Shanghai Institute of Nutrition and Health(SINH), Chinese Academy of Sciences(CAS)
- Address: 320 Yueyang Road, Shanghai, China 200031
- Email: liting@picb.ac.cn;zuoling@picb.ac.cn
Citation:
If you use TonguExpert in your research, please cite:
Li, T., Zuo, L., Wang, P. et al. TonguExpert: A Deep Learning-Based Algorithm Platform for Fine-Grained Extraction and Classification of Tongue Phenotypes. Phenomics(2025). https://doi.org/10.1007/s43657-024-00210-9